¿Por qué son importantes los SLM?
Hace un par de años muchos descartábamos los modelos pequeños. Pensábamos que el cerebro más grande, es decir, los LLM, con inmensos centros de datos y miles de millones de parámetros, eran los que ganaban. Y sí, es cierto. Lo hacen, pero a un coste muy alto y, a decir verdad, no siempre son los más útiles. Gracias a las aportaciones de sistemas como Llama (Meta), Qwen (Alibaba) o DeepSeek, hemos visto que con estos modelos más reducidos podemos obtener rendimientos excelentes.
La clave técnica es la cuantización, es decir, reducir el tamaño y la complejidad del modelo. Se han desarrollado modelos que pueden ejecutarse en un móvil de 8 GB, interactuar con sistemas externos o bases de datos con precisión, y superar el rendimiento de modelos diez veces más grandes. Es lo que en la charla llamamos la "navaja suiza" de la IA: versátil, ligera y potente cuando le damos la arquitectura adecuada.

«Los LLM obtienen mejores resultados, pero el coste de inferencia es muy alto. Destilando y quitando capas de entrenamiento a esos modelos podemos tener utilidades interesantes a un menor coste.»
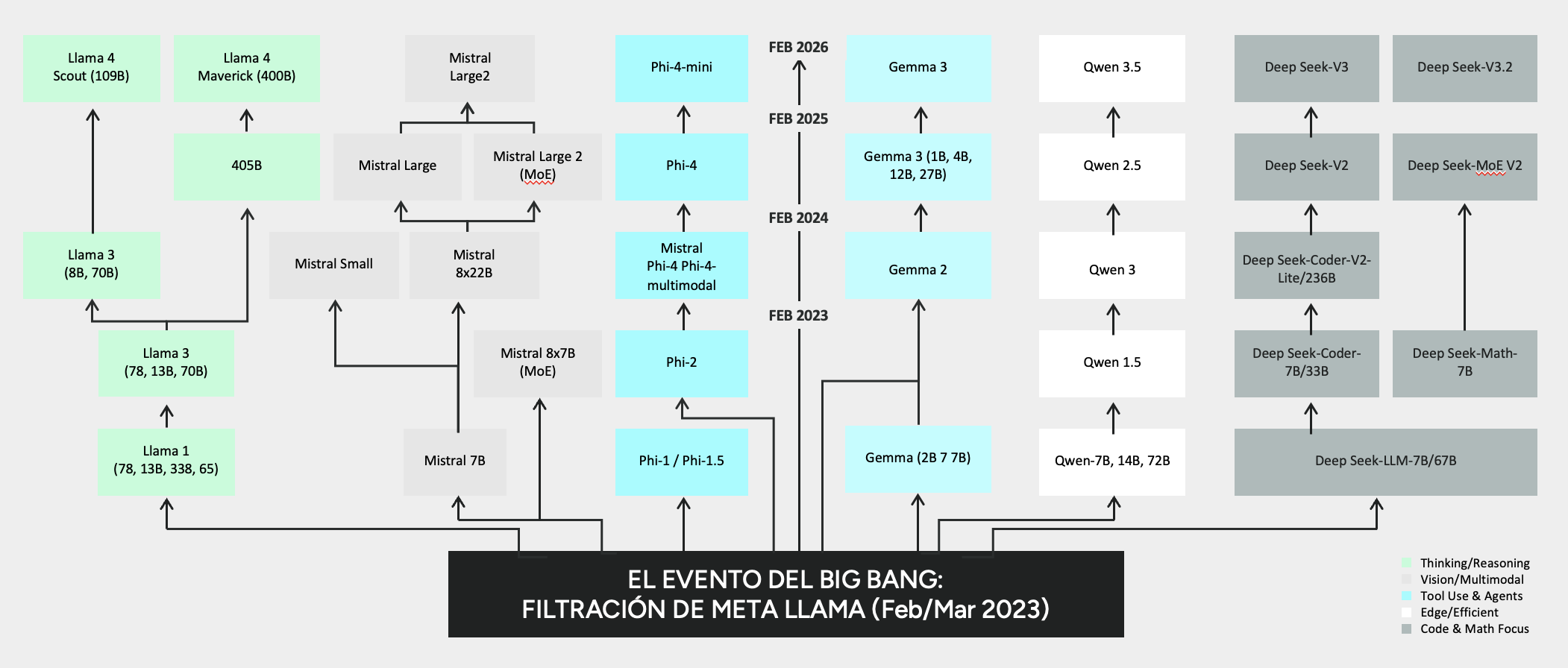
Evolución del open source en SLMs & LLMs (2023-2026)
¿Qué ventajas ofrecen estos modelos?

Privacidad mediante ejecución local. Al funcionar en tu propio hardware, los datos sensibles nunca salen de tu control.

Control total sobre precio y disponibilidad. Evita la dependencia de APIs externas, eliminando riesgos de caídas de servicio o cambios inesperados en los costes de suscripción.

Especialización extrema con Fine-Tuning económico. Continuar ajustando un modelo preentrenado con datos más específicos puede elevar la precisión en tareas concretas.
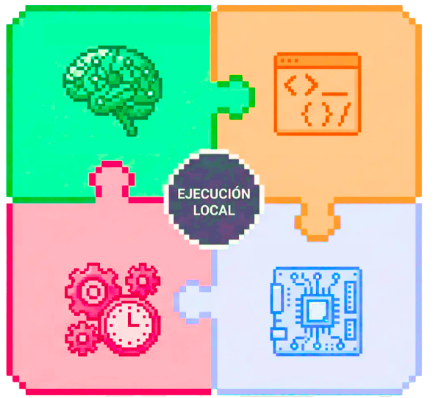
Los 4 pilares necesarios para ejecutar IA en local
Estos cuatro componentes deben encajar correctamente para lograr una ejecución exitosa:

«La cuantización funciona como la compresión de una imagen: puedes reducir el tamaño del archivo a la cuarta parte y el ojo humano apenas nota la diferencia. Con los modelos de IA ocurre lo mismo, el rendimiento es prácticamente equivalente al original a partir de un umbral.»
¿Cómo podemos hacer un small agent fiable?
Aunque los modelos pequeños necesitan más guía que los grandes y en muchas ocasiones “los debes llevar de la mano”, pueden impulsar agentes que pasen a la acción y hagan tareas, como las que hemos mencionado al principio. Para lograrlo es importante tener en cuenta tres parámetros clave:

Contexto. Como la memoria es más reducida, aún tiene más protagonismo que en los modelos grandes. Existen técnicas consistentes, como recortar, resumir o cherry picking (seleccionar sólo los datos que convienen), para indicar bien qué información se incluye en cada momento y evitar que el agente se pierda o se repita.

Arquitectura. Es la parte más crítica. Para que el sistema sea totalmente fiable, debemos tener muy clara tanto su estructura como el orden en que ejecuta sus procesos. Estos modelos ya no utilizan la arquitectura Re-act (basada en que el agente “piense y actúe” repetitivamente), sino que funcionan mejor a través dos enfoques. Uno es el de grafos de ejecución, en el que el agente avanza tomando decisiones entre diferentes caminos predefinidos. Y el otro es la orquestación, una técnica cada vez más popular, que organiza y dirige tareas estableciendo una jerarquía clara.

Prompting. El system prompt es la clave para el correcto funcionamiento de este tipo de modelos. Incluye el título y la descripción y deben ser concisos, no excesivamente grandes y deben mostrar reglas claras y concretas con ejemplos de casos de uso del agente. Todo ello ayuda a tener mayor precisión y calidad en las respuestas.
A un LLM le podemos decir “hazme la contabilidad” y seguramente la haga. A un SLM ni de broma. Pero sí podemos hacer grados de pasos y controlar mucho más el proceso, que es lo que nos gusta a los programadores, para lograr que haga ese mismo flujo. Requerirá más trabajo sí, pero el resultado podría ser equivalente con un coste mucho menor.
Lo que un nanoagente puede hacer hoy en una empresa
Como ya defendimos en nuestra intervención en el T3chFest, estos modelos no son teóricos, bien orquestados pueden ser una realidad en producción. De hecho, en el departamento de Innovación Aplicada del grupo Cuatroochenta los hemos estado testeado para algunas tareas concretas.
Aprender a construir y orquestar modelos pequeños puede llegar a ser estratégico. La IA no tiene por qué estar solo en la nube, puede ejecutar en cada dispositivo, en cada servidor o en cada proceso empresarial. Los nanoagentes tienen limitaciones. Lo sabemos y somos conscientes. Pero el abanico de posibilidades que abren es amplio para no perderlos de vista.

«El secreto no está en el modelo sino en la orquestación y cómo gestionamos los datos.»
En el grupo Cuatroochenta exploramos tecnologías avanzadas y emergentes para detectar oportunidades y convertirlas en soluciones útiles y reales.
Conoce los proyectos de 480LABS: I+D
